
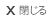
数百万冊におよぶ書籍の単語を、ビッグデータと捉えたら何が見えてくるのか? Google がスキャンした大量の書籍で使われている単語・フレーズの使用頻度を年ごとにプロットするシステム「グーグル・N グラム・ビューワー」。本書はこのビューワー自身の開発者によって、「カルチャロミクス」と名付けられた全く新しい人文学研究を紹介した一冊である。本稿では、この研究の背景となる「経済物理学周辺の最前線を、東京工業大学の高安 美佐子氏に解説いただいた。(HONZ編集部)

コンピュータを使った新しい文章の読み方
通常、文章の書き手は、どういう順番で話を展開すれば、読み手に内容を伝えられるかを考えながら言葉を一つひとつ選び、それらをつないでいく。そして読み手は、初めの単語から順番に読み解き、その内容を理解する。しかし、本書のテーマとなっているように、コンピュータを用いた分析技術を用いれば、人間が文章を理解する方法とはまったく異なる数理的な方法で文章を“読む(解析する)”ことができる。文章をその最小の構成要素である単語に分解し、現れた単語の数の変動や分布から定量的に文章の特徴を抽出する方法である。
解析対象の文章は、かつては個々の公式記録文書や小説や雑誌や新聞記事であった。それを本書著者の研究は、グーグル・ブックスのデータを利用して過去数世紀分の書籍、数百万冊を対象にできるようにし、それを一般の人でも利用可能なものにした画期的なものだ。だが、その研究成果であるグーグル・Nグラム・ビューワーは、残念ながら日本語には対応していない。
とはいえ、日本でも、インターネットや携帯端末の普及により、収集可能な文章が大きく広がった。インターネットを日常的に使う人の数は、現在、日本だけでも一億人を超え、ブログやSNSなどの利用者も数千万人のレベルになっている。これだけ多数の人が毎日利用しているので、ブログやSNSなどの書き込み記事を分析することでさまざまな興味深い情報を引き出すことができる環境が実現している。また、インターネット上では、新たに書き込まれたブログなどの記事を自動的に収集するシステムがさまざまな企業によって提供されており、日々、どのような言葉が使われているかを網羅的にリアルタイムに近い状態で観測することができる。
もちろん、このようにコンピュータを利用し、統計的な手法を用いて文章を解析して得た知見は、人間の脳が行っているような文章の理解とは異なるが、人間には読み取れないような発見、たとえば「ブームに見られる人間の集団行動の特徴」「言語が持つ普遍的な特徴」などが見えてくる。本書著者らの研究は、数年単位の時間スケールのものだが、その研究で見られるような人間の集合的な行動の特徴が、ネット上の書き込みの分析では、数週間・数日・数時間の時間スケールで観察できるのである。
言葉から見える、ブームに見られる人間の集団行動の特徴
従来、人々がどのようなことを考えているのかを知るためには、電話や街頭でアンケートを行うなど、手間とお金をかけて調査していた。しかし、インターネット上のブログ記事を活用すれば、人々の生活の様子などの膨大な記録を調べることが可能となる。ブログの解析は、数千万人の生活をリアルタイムで観測する電子顕微鏡の役割を担うことが期待され、消費者の声を拾うために企業側でも利活用が盛んに行われている。
1日ごとに、たくさんの人によって新規に書き込まれたブログの記事を寄せ集め、書き込まれた文章を単語に分解し、それぞれの単語の出現頻度を時系列にする。その時系列変化を解析することで、人々の関心の移り変わりを特徴づける単語を自動的に抽出する研究も盛んに行われている。たとえば、「KY (空気読めない)」という言葉は、女子高生などの間で流行していた造語であったが、2007年以降、急激にメディアなどで使われはじめ、指数関数(tを時間、aを定数としたとき、y=a^tの形の関数)的に使用頻度が増加した。2008年にピーク期を迎え、その後、ゆっくりと減衰し、日常的な日本語の単語として定着している様子が観測できる。人気がある芸人さんなどの話題や、流行しているスイーツなども、KY と類似した関数でブームを迎える。まさに社会の中でどのようにブームが形成されていくのか、その関数形が観測できる。
ブログの中の単語の出現頻度の時系列は、その特徴から次の4つに大雑把に分類することができる。
1 非流行語——流行で使われている言葉でなく、出現頻度は一定値のまわりでランダムに時間的にゆらぐ変動(「しかし」「ともかく」など)
2 流行語——時間とともに指数関数的に数年単位で増加し、ピークを迎えて、指数関数で減少する変動(「KY 」、「パンケーキ」、映画タイトルなど)
3 ニュース語——突然、不連続的に劇的に増加し、その後、べき乗の関数(y=1/t^aの形の関数)で減少する変動(「津波」、「マイケル・ジャクソン」など)
4 イベント日語——特定のイベント日付に向かってべき乗で増加し、その後、べき乗で減少する変動(「クリスマス」、「こどもの日」など)
この中で3の「ニュース語」の典型的な事例として、図1に、「津波」という単語の出現頻度の時系列を紹介する。2011年3月11日、東日本大震災の日よりも前には、津波という単語は日常語の一つで、少ないが安定した数でブログに書き込まれていた。震災の当日、この単語の出現数は何万倍にも増加し、時間とともにゆっくりと減少していった。グラフを両対数でプロットするとほぼ直線的に書き込み数が減少しており、べき関数(y=1/t^aの形の関数)で近似することができる。この関数形が持続するものと仮定すると、津波という言葉の出現数が以前の日常語のレベルになるまでに、およそ25年かかるという推定ができる。企業不祥事などのニュースも、一気に話題になり、同様の関数に従うことが知られている。
4の「イベント日語」の典型は、たとえば、2月14日の「バレンタインデー」のようにイベントの日程が決まっているような単語で、その日に向かって期待がどんどん高まり、急激に口コミ数が増加する。しかし、イベントが終わると、急に関心がうすれ、時間的に急速に減衰するような振る舞いを示す。この関数形は、ちょうどその当日に発散するような、べき関数で近似できることが多いことがわかっている。このような特性を利用すると、イベント当日までにどれくらいの書き込み数があるかを、ある程度予測することが可能となる。通常で観測できるブログにおける単語の出現頻度の時系列では、1から4までの振る舞いの融合で、複雑な振る舞いをすることが知られている。
最近、そのような時系列変化を、簡単な規則に従いつつランダムに動くたくさんの人間の行動のモデルを構築し、シミュレーション実験を行うことで理解できるようになってきた。そのようなモデルを用いると、どのような関数でブームが進行し、イベントなどを開催する効果がどのようにあるのかなどを、シミュレーション実験であらかじめ定量的に予測できるようになる。
このようなシミュレーションによる研究から、2の指数関数で口コミ頻度が増減するブームは、直近の期間での増加分や減少分に比例して、新たにその言葉が書き込まれるようになるというメカニズムが背後にあることがわかる。つまり、どのくらいその言葉がソーシャルメディアなどに出現するのかに敏感に反応して、個々のブロガーが新たにその言葉を用いる確率が変化するのだ。ブームの背景のメカニズムは、たくさんの人間が集まったときの集団行動の特質として、金融市場の価格変化などいろいろな現象との類似性があり、ビッグデータが利用可能な時代の新たな社会科学として関心が持たれている。
言語が持つ普遍的な特徴
コンピュータを用いれば長い文章でも容易に、文章の初めから数えて何単語目に、今まで使ったことのない新しい単語が出現したかを調べることができる。文章の書き出しでは、当然、すべての単語が初めて出現した単語となるが、文章の中ほどになると、すでに使った単語を繰り返すことが多くなり、新しい単語の出現頻度は低くなる。何十万語からなるような文学作品などを調べてみると、最後の方になっても、なお新しい単語がときどき出現する。このような特性は、「最初からN単語目までの中に使われている異なる単語の数」をF(N)としてこれを計算することによって定量化することができる。そして、この関数 F(N)の曲線の形から、Nを無限大にした極限を想定することができ、書き手の潜在的な語彙力を推定することもできる。いわゆる文豪の文章の場合には、この関数は、Nが何十万という値になっても一定に増加を続ける傾向があり、潜在的な語彙数が非常に多いことがわかる。一方、文学作品などと比較すると、手軽に書き込めるブログなどでは、用いられている語彙数が少なく、比較的小さなNの時点で、F(N)の増加が止まる傾向がある。
しかし、文豪であっても、素人の書き手であっても変わらない特性もある。さまざまな言語で確認されている“言語が持つ普遍的な特徴”の筆頭が、本書にも登場するジップの法則である。「文章を単語に分解し、出現頻度の多い順にランキングすると、第k番目の単語の出現頻度が1/kに比例する」というジップの法則は、さまざまな言語で書かれた書籍などの解析から、かなり普遍的に成立することが知られている。最近では、作家が書いた小説でなくても、ブログ記事のような一般人の電子的な書き込みであってもこの法則が成立することが確認されており、人間が用いる言語の普遍的な特性として知られている。
ブログ記事では、ランキングに出てくる単語そのものは、書き手の個性によってかなり異なる。料理好きのサイトであれば料理名や素材名などが頻繁に登場し、また、漫画やゲームに関する記事であれば、作品名や登場キャラクター名がたくさん出てくる。それにも関わらず、ランキングごとの単語の出現頻度は、おおよそジップの法則を満たすというのは、驚きである。
ジップの法則が成立するのは、単語の出現頻度に限らない。たとえば、日本国内には100万社以上の企業があるが、それらの企業の年間売り上げの分布もジップの法則に従うことがデータから確認されている。企業を売り上げの大きい順にランキングをすると、ランキングがk番目の企業の売り上げは、おおよそ、ランキングが1位の企業のk分の1になっているのである。この特性は、日本だけでなく、世界のさまざまな国でも成立していることが知られている。その他にも、人口などで見た都市の大きさ、ヒット曲の売り上げなど、社会で見られるいろいろなランキングがジップの法則に従っており、その数理的な背景の理解に注目が集まっている。
ジップの法則とべき分布
ジップの法則は、数理的には、「べき分布」とよばれる分布の特殊な場合である。べき分布に従う身近な例は、ガラスを硬い床に落として大小さまざまな破片が生じた際の大きさの分布である。数少ない大きなゴロゴロとした破片、結構たくさんある中くらいの大きさの破片、そして、数えきれないほどの小さな破片にいたるまで幅広いスケールに大きさが分布する。このような分布は、「累積分布」とよばれる量を観測することで、特徴を定量的に評価しやすくなる。累積分布は、注目する大きさをxとしたとき、任意に選んだサンプルの大きさがxよりも大きい確率、P(>x)によって定義され、この関数がべき関数1/x^a に比例するとき、「指数がaのべき分布」とよぶ。ジップの法則とは、この指数aがちょうど1の場合である。
ランキングと累積分布は密接につながっている。あるサンプルの大きさがx、ランキングがk位であるということは、xよりも大きなサンプルが自分自身を含めてk個あるということを意味する。したがって、ランキングの順位を全数で割るだけで累積分布P(>x)が得られる。
指数aが1でない場合にまで拡張すると、べき分布が観察される物理現象は、非常に広範な領域に見出すことができる。ガラスの破片の場合には、xを破片の体積とすると、指数の値はほぼ3分の2であることが知られている。これと同じ指数が3分の2のべき分布は、小惑星の大きさの分布、地震のエネルギーの分布においても確認されている。河川の流域の大きさの分布、樹木の枝の大きさの分布などもべき分布で近似される。海の中の魚の群れの大きさの分布も、大気中を漂う微粒子であるエアロゾルの大きさの分布も、べき分布に従うことが知られている。
社会現象ではジップの法則で紹介した企業の大きさ分布、都市の人口の分布のほかにも、本の発行部数、ヒット曲の売れた数、株価や為替の市場価格の変動や個人の所得の分布、銀行間で送金されるお金の量などもべき分布で近似される。これらの多くの例からもわかるように、人間社会や経済現象の場合には、とくにべき分布が多く観測される。企業の売り上げの分布では指数はほぼ1であるが、企業の大きさは、売り上げだけでなく、従業員数や取引相手の数でも測ることができる。従業員数の分布で見ると、指数は 1.3程度、取引相手数の分布でも指数は1.3程度になることがデータから確認されている。ちなみに、取引相手数の分布がべき分布に従う特性は、複雑ネットワークの科学では「スケールフリー」とよばれる重要な特性である。スケールフリー性を有する複雑ネットワーク構造は、空港間の路線のネットワーク、人間関係のネットワーク、インターネットのホームページ間のリンク関係などさまざまな分野で見出されており、複雑なシステムに関する基本的な構造の理解を深めるための科学的研究が進められている。
書き込みの解析で社会のレジリエンスを高める
日本語で書かれたブログ記事を収集して解析することで、人々がどのような感情に関わる言葉を書き込んでいるのか、その時間変動を定量化することもできる。POMSとよばれる心理分析の手法にしたがって、「緊張、抑鬱、怒り、活力、疲労、混乱」の6つの基本的な感情に対応する単語群を特定し、それらの単語の増減によって感情の変化を定量化できる。たとえば、2011年の東日本大震災をきっかけに、書き込みに見られる感情が大きく変わったことがわかる。
感情と経済活動は関係が深い。感情の中で、とくに「活力」の変動は、株価ともかなり連動性が高いことがわかっている。また、景気に関する書き込みの良し悪しと景況感を表す既存の指標との相関関係を調査し、景気と連動するような口コミの指標を計算する研究も現在進んでいる。順調に研究が進めば、これまで集計に時間がかかっていた景気指標を、リアルタイムに近い形で提示することができるようになる可能性もある。このような試みは企業などでもすでにいくつか行われているが、本当の相関ではない偽相関のある単語をたくさん収集してしまったり、あるいはサンプルデータの特徴に過剰に適合した予測をしてしまうオーバーフィッティングにより、未来のデータとは整合しなくなるという問題が生じやすく、科学的に慎重に単語選びと数理モデル化を行う必要がある。
もうひとつ、関連した分野の研究として、ブログやSNSでの誤情報の拡散による社会的な損失を減らす方法の開発に関する研究プロジェクトを紹介する。2011年の大震災のときに実際に起こったことであるが、東京湾沿岸のガスタンクが爆発した直後、「毒を含んだ雨が降る可能性があるからカッパなどの雨具を用意した方がよい」という誤情報がSNSを通して広まった。「天然ガスなので毒は発生しない」という正しい情報を発信する人もいたが、震災直後で過剰に人々が誤情報に反応して、誤情報の方が速く広く拡散してしまった。その後、ガスタンクのある市の公式のホームページにこの誤情報のことが発信され、それを契機に急速に誤情報を訂正する書き込みが増加し、まもなく完全に鎮静化した。このような噂の伝播は、従来は口伝えだったので記録が残らなかったが、ブログやSNSを使った場合には、タイムスタンプ付きの時系列として記録が残るので、後からどのように噂が拡散したのかを科学的に検証することができるようになった。

M.Takayasu et al, PLoS ONE 10(4): e01221443(2015)
インターネットの中の噂の伝播を数理モデル化し、どうすれば誤情報をいち早く修正し、鎮静化することができるかをシミュレーションによって解明しようという研究を、私達は、今、イスラエルの研究チームと共同で進めている。上記のガスタンク関連の噂は大きな害を及ぼすことはなかったが、噂はときとして、人々を実際の行動に駆り立てることもあり、そのため社会に大きな損失を生じさせる可能性がある。とくに災害時など、人々が不安な感情状態にあるとき、どのようにすれば人々が冷静さを保ち、正しい情報を選択し、いち早く平穏な状態に回復することができるかという研究は、社会のレジリエンスを高くする重要な基盤となる研究であると期待している。